Content Classification System
Benefits
- Reliable and high quality information
- User Feedback Module
- AI & ML Based Automated System
Challenges
- Reliable
- High quality information
- User Feedback Module
- AI & ML Based automated system
The analytics product after integration prior indexed data for info-graphics aimed at providing decision support systems.
Products and experiences that are pleasant to use can be created by UX services. We help leading companies and startups enhance their content creation capabilities and utilise digital marketing initiatives to achieve their business goals.
Project Overview
1. Inputs
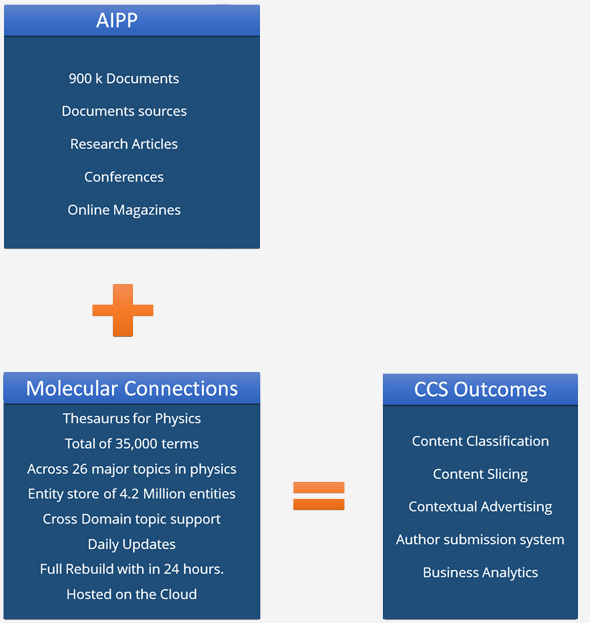
Article formats – The system successfully ingests both PDFs and xmls with varied content intensity
Training – About 900,000 scientific articles were ingested in the development phase, with 145,000 being used as a training set for the machine learning module.
2. Machine Learning
Initial training – Initial training of the machine learning model with a recall of 50% and achieving an average of 50 tags per article
Specificity training – Weighing contextual terms over other valid terms
Heuristics training – Precision of 51% and a recall of 58%
Lexicon/Ontology enrichment – Entire set of 900,000 articles were leveraged to refine and enrich the lexicon.
Ancillary training – Machine learning models for tagging chemicals and chemical compounds (A precision of 85% and a recall of 89% on its own.
3. Model optimization
Added rule sets to improve on contextual tagging, including complex rules like acronym rules, heuristic weight age of terms and generic tagger etc.,
Methodology
Highlights
A sound ontology that is a perfect fit for automated fingerprinting alongside traditional browse capabilities on platforms.
Plug and play automated system with feedback ingestion capabilities.
APIs for the Lexicon component which are used at the Indexing level as well as the backbone of referee finder and contextual advertising within Scitation platform.
Flexible cores – Lexicon and miner capabilities to accommodate to new requirements/ adjust to new scope horizons keeping the basic functionalities intact.
Real-time versioning, update and change management/tracking systems.